The diagnosis & self-heal
infrastructure for RAG Agents
Built for trace-level supervision of your agents at scale.
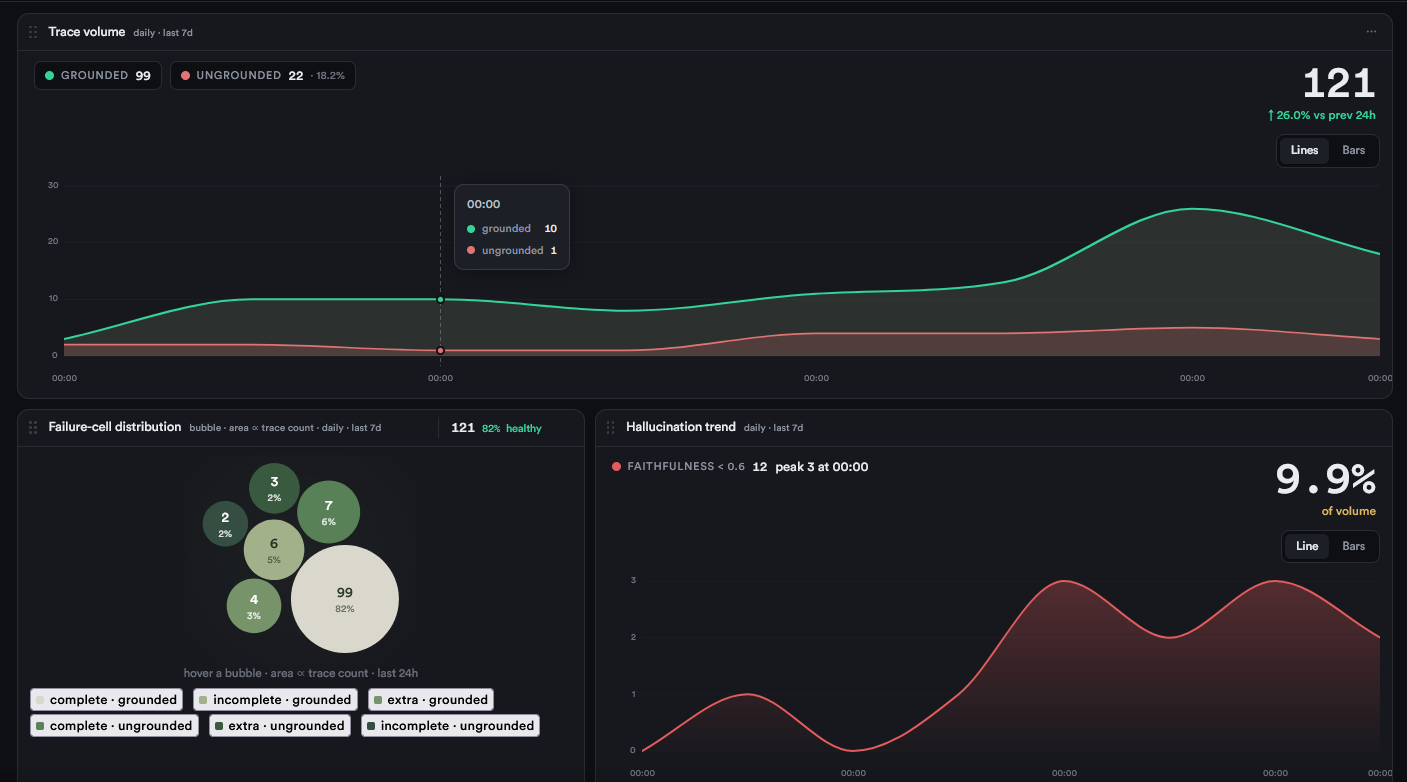
Built for trace-level supervision of your agents at scale.






Most tools flag the failure. Veralith fixes it.
Detection is only half the loop. Veralith turns the fix into a pull request — written by your own agent, in your own repo, over MCP.
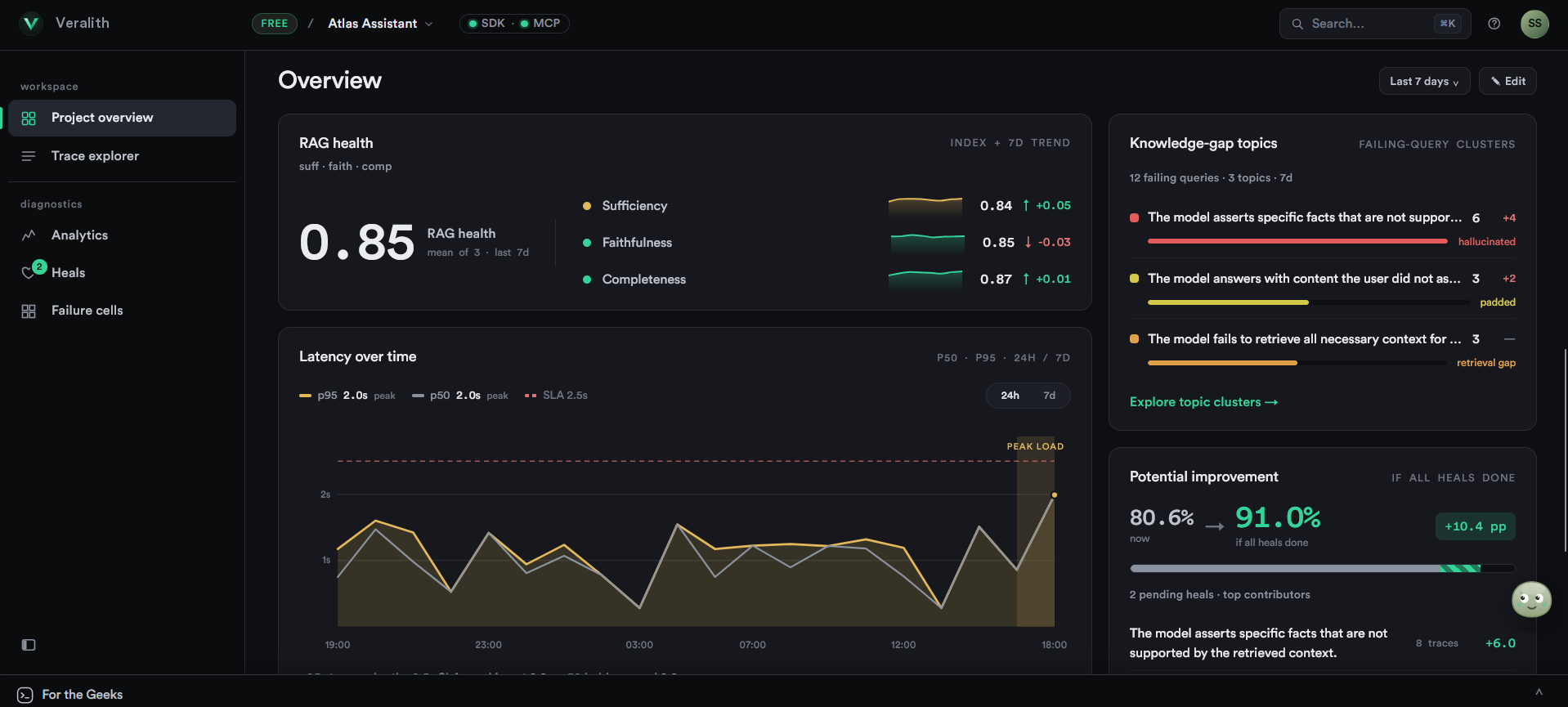
See how self-heal works“Faithfulness: 0.33” tells you nothing. Veralith names the failure — and the fix.
Explore the diagnosisFire-and-forget on every answer in production — no added latency, no broken requests, ever.
Reliability guaranteesAtomic claims, judged one by one — see exactly which broke.
One line, or the zero-change LangChain adapter. Any stack.
Self-heal runs in your repo over MCP. We never see your code.
Four steps close the loop — instrument once, and Veralith diagnoses, heals, and monitors every trace your RAG agent serves.
Veralith is in active pilot — free for early teams while we learn what to charge. You'll get plenty of notice, and a say, before any pricing lands. Every tier includes the full diagnosis engine.